前言:本文有俩个目标读者,一是不懂编程,想了解编程“介究竟是个嘛(第四声)”的人;二是有编程经验,不会python,但希望学习python或者需要使用题目所示功能的人。
PS:长(luo)文(li)多(luo)图(suo),流量党慎入
PPS:要直接看编程部分的请直接阅读第三章前半部分和第四章之后

_(:?」∠)_大家好,新的一天,有没有在简书更文学编程呀?
_(:?」∠)_有没有更口水向往寄几一直在默默点喜欢的作者呀?
_(:?」∠)_有没有在写作编程的入门之路上感到万分沮丧,甚至开始怀疑人生呀?
_(:?」∠)_恩?你问我为什么躺着?emmmm,我想这个角度可能会有惊艳的写作思(nao)路(dong)……

开始在简书写作快一个月了,看了不少知名作者分享自己的写作经验,可到了自己要写的时候,却发现文思如癫痫,下笔如瘫痪(真相是文思和下笔都瘫痪了),这可怎么办呢,这岂不是离写作的梦想更远了?于是我决定用python把喜欢的作者的所有文章全部爬下来仔细阅读研究,看看有没有什么写作的技巧(感觉我要火啦!好激动!)。
会不会很多人一看到要写程序来研究就准备关掉页面了?(废话,好多人看标题就掠过了)根据分享爬取简书数据推测
简书大约有235w的用户,其中关注程序员栏目的有近44w,占总用户的18%,每11个人中就有2个人在关注编程相关信息,说明简书中程序员对程序员感兴趣的人比重不在少数,可不知道有多少人,看着栏目里的大佬们写得天书一样的编程经验,望而却步。
专家盲点(expert blind spot)就是对一个事物知道的越多,就越发不记得“不知道这个事”的情形。
作为一个尝试过C,尝试过Java,尝试过MATLAB,尝试过Html、CSS,并无一例外的全都从入门到放弃的人,我实在太懂小白们啦!我在刚学习编程的时候,一直是黑人问号脸,(⊙…⊙)介是嘛?(((;???;)))介又是嘛?_(:3」∠?)_what are you 说啥捏?!越是专业的大佬们说出来的术语,越是……听不懂。

很久前画的关于《绘画.从入门到放弃》的条漫,请叫我灵魂画手
所以在我学习python的过程中,想要用更简单易懂的语言告诉不会编程的你编程是怎样的。(快!毫无保留地夸我!)
1.基本概念
计算机语言是指用于人与计算机之间通讯的语言,如今通用的编程语言有两种形式:汇编语言和高级语言,高级语言是绝大多数编程者的选择。
这里讲的编程语言都是高级语言,高级语言有很多种,Java,C,PHP,Ruby,Python…
编程语言的逻辑是基本相同的,就像不管是写新闻,还是写日记,还是写小说,都是人吃饭,不会是饭吃人(灵异小说除外O__O "…)。
编程语言的语法会有各自的特点,就像中文说我今天很开心,而英文说I'm happy today(直译“我是开心今天”)。
编程语言的功能侧重点也不同,objective-c主要用于ios开发,php用于web开发,python主要用于写爬虫(我编的),就像用认真的语气写思想汇报,用严谨的语气写论文,用逗比的语气写python教程一样(逃)。
2.明确目标

简书的大V作者们在写作经验分享中不断地强调着,不管你想写什么,先写起来,多尝试多练习,渐渐就找到方向了。
不过毕竟在写作之前也说了几十年的大白话了,就算文笔再差只要认识字自然可以直接开始写,可是编程语言零基础的话是什么都不知道,就算想写,怕也是无从下笔,可编程语言知识又看不懂(碎碎念……
来自日本已经82岁的若宫正子老奶奶成为了2017年苹果全球开发者大会年纪最大的开发者,因为她发现ios平台没有适合老年人使用的app,所以开始自学编程,进行ios开发。
在不了解编程语言的时候,看编程语法是肥肠枯燥的(我都快枯萎了),而且很容易学完就忘,可为什么老奶奶都能够学会呢,因为她要开发老年人用的app,有了目标,就有了动力,所以就需要明确目标,你希望通过编程做什么。
推荐python一则因为它的语法自由度高,语言简洁清晰,适合初学者学习;二则因为…当然是因为它可以做很多肥(ke)肠(yi)有(zhuang)趣(bi)的事情啦!每次看到别人拿着什么大数据,各种图表、分析,快告诉我你真的一点也没有羡慕吗?!
零基础开发一个app可能需要几个月,但零基础学python到做点小爬虫可能只需要几天(诱不诱人?心不心动?),而在互联网强大的开源环境下,写出大爬虫也是指日可待啊(快醒醒)。
好了,不废(zuo)话(meng)了(擦口水),写作没题材无从下笔我帮不了你,爬虫的目标已经选好啦,来爬一爬简书大V们写的文。
3.撰写提纲
为什么要在编程之前写提纲?
就像写小说一样,分段,分章节,分情节,是为了搭建故事的框架,为了更好的讲故事,也是为了防止自己写着写着就想不起来自己为什么要这么写了(我承认我是最后一种)。
在写提纲这件事上,编程比写小说简单多了,因为“代码是凝固的文字,而小说是有张力的文字”(引自知乎无色方糖),一旦你知道自己要用编程做什么,代码的堆砌是有迹可循的,但即使你知道小说剧集的终点是什么了,怎么写得精彩绝伦,那就不得而知了,这样想是不是觉得编程比写小说容易多啦?
我以前曾经说过,爬虫是模拟用户上网行为的一种程序,所以我们需要思考的就是在得到作者文章合辑pdf之前,我们都做了什么?
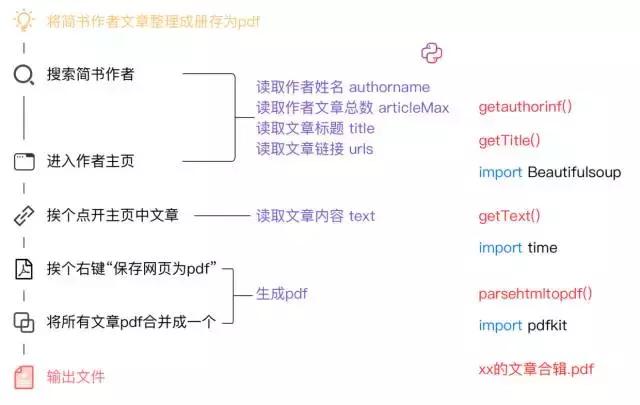
当爬虫工作时,它在做什么
没有学过编程的你,看懂了哪一步?黑字?紫字?还是红字?或者蓝字?
黑字就是一个对我们要人肉完成生成作者文章为pdf这个目的时需要做的。
紫字是从机器角度去思考爬虫需要做的。
红字是编程中的函数,每一个功能都是有一个一个函数运行完成的。
蓝字是从外部引入的功能模块。
是不是已经蒙圈了?
我们换个角度来解释。
本米打算写一部惊世骇俗的史诗级小说,“拥有绝世美颜的女主因不堪继母的百般刁难发奋图强一举考入清华大学飞禽系脱离家庭并靠自己不畏艰苦的精神一边兼职神奇动物饲养员一边读书最终以优异的成绩进入动物城青眼白龙村母龙联合会工作并在那里好巧不巧地因为养殖经验丰富受到了有着童年阴影的魔法界公众人物也就是男主角的崇拜男主盛情邀请女主参观他的妙蛙种子试验田的时候附近地面遭到了外星飞船的撞击女主被外星人附身失去原本记忆男主远走他乡为其寻找解救之法却不小心穿越至石器时代又在疯狂原始人的帮助下被神仙发现神仙了解男女主的故事后大为感动仙杖一挥赶走了外星人并许了他们三生三世的兄妹情缘”……

听到神奇动物、青眼白龙、妙蛙种子这些词的时候,有没有觉得很熟悉,有没有直接脑补出一段记忆深处早已存在的剧情?这就是类似于编程中外部引入的功能模块,这个模块早已存在了,它也并非我写的,刚好它拥有我需要的功能,所以我就将它引入到我正在编写的代码中,这样它本身包含的功能我就可以直接使用了。
仔细分解故事,大致可分为女主家庭篇、女主大学篇、女主工作篇、男主篇、男主女主相识篇、外星事故篇、千里解救女主篇、大团圆篇,这里的人物角色,代表着程序中的参数;每一个故事的章节,就代表着一个的函数。不同的函数代表着不同的功能,函数与函数之间相互联系,完成程序的任务(类似于展示故事的情节),传递共同的参数(可以理解为角色贯穿整个故事)。
程序语言中还有一些内置函数,内置函数是程序本身自己就有的函数,就像中文写吃东西用吃饭,英文用eat,日文用食べる。
通过对内置函数的使用,模块的调用,以及函数功能的搭建,就组成了一个完整的程序。
4.构建代码
本段开始建议有编程基础再阅读,当然你没编程基础也看得懂那我也敬自己的口才是条汉子。

4.1 伪装浏览器打开页面
defgetPage(url):#获取链接中的网页内容 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36' } try: request = urllib2.Request(url = url, headers = headers) response = urllib2.urlopen(request, timeout = 5) page = response.read().decode('utf-8') return page except (urllib2.URLError,Exception), e: if hasattr(e, 'reason'): print'抓取失败,具体原因:', e.reason response = urllib2.urlopen(request,timeout = 5) page = response.read().decode('utf-8') return pageuser-agent可以理解为爬虫的浏览器马甲,披上了这个浏览器马甲,爬虫就会像我们平常上网时打开浏览器输入网址就可以看到网页一样得到需要的网页内容,这是为了应对低阶的反爬虫技术所采取的措施,关于爬虫和反爬虫的战争,改天再唠。

4.2 分析个人主页
抓一个简书作者,怀左同学的网址是这样的“http://www.jianshu.com/u/62478ec15b74”,多观察几个个人页地址就会发现只有“http://www.jianshu.com/u/”后面的那一串字母和数字组成的字符串会有变化。
简书个人主页内包含了作者的信息,文章总数,也包括了文章的标题,往下拉页面,会发现文章不断的加载出来,应该一直往下翻可以翻到第一篇文章,但如果右键查看源代码,就只能看到已经加载出来的文章源码。
文章是动态加载的,需要在chrome浏览器右键检查,在弹出窗口中选择network,这时继续下拉页面,观察左下角的列表变化,里面有一个包含page字样的链接文件,不一定在xhr分类下,不过一般就那几个分类里。
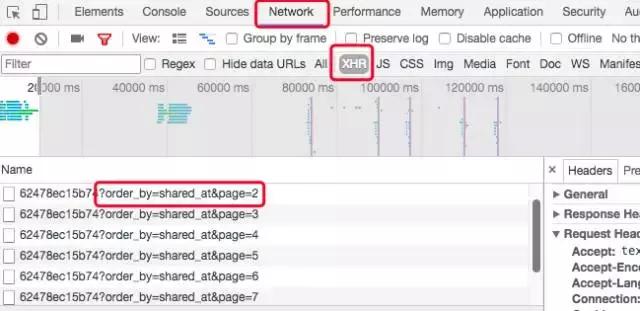
加载出的页面是从page=2开始的,试着打开http://www.jianshu.com/u/62478ec15b74?order_by=shared_at&page=1,发现可以获得与http://www.jianshu.com/u/62478ec15b74内容一样的页面,从而得到爬取所有文章列表的网页url。
4.3 获取作者信息、文章链接
节选个人页源代码
<pclass="title"><aclass="name"href="/u/62478ec15b74">怀左同学</a><spanclass="author-tag"><iclass="iconfont ic-write"></i> 签约作者</span></p>作者的姓名在title.name下,正则表达式为:
pattern = re.compile(u'<a.*?class="name".*?href=".*?">(.*?)</a>')节选个人页源代码
<pclass="info"><ul><li><pclass="meta-block"><ahref="/users/62478ec15b74/following"><p>17</p> 关注 <iclass="iconfont ic-arrow"></i></a></p></li><li><pclass="meta-block"><ahref="/users/62478ec15b74/followers"><p>63600</p> 粉丝 <iclass="iconfont ic-arrow"></i></a></p></li><li><pclass="meta-block"><ahref="/u/62478ec15b74"><p>244</p> 文章 <iclass="iconfont ic-arrow"></i></a></p></li>文章数隐藏在info.meta-block下,但meta-block下会匹配到的值不止一个,用于区别值的几个href都是根据作者生成,不适用于所有作者,所以选择将匹配的值保存在list中,查看源码可推出需要的值在list中第三个,于是返回list[2]的值。
pattern = re.compile(u'<p>(.*?)</p>')metablock = pattern.findall(page)titleNum = int(metablock[2])节选个人页源代码
<a class="title"target="_blank"href="/p/c2a4a3b3490e">通过自律,我拥有了一个高配的暑假</a>这里匹配的是文章的标题,可以看出前面的href中的值"/p/c2a4a3b3490e"对应着文章链接的尾部,一并保存并转为网址形式,将匹配到的值存入1个list中(下面的代码还匹配了发表文章的时间)
pattern = re.compile(u'<span.*?class="time".*?data-shared-at="(.*?)+08:00"></span>.*?' + u'<a.*?class="title".*?href="(.*?)">(.*?)</a>',re.S)titles = re.findall(pattern,page) for title in titles: titlelist.append([title[0],'http://www.jianshu.com' + title[1],title[2]]) print'正在读取第' + str(num) + '篇文章链接' num +=14.4 将网页转为pdf
咦,这么快就要转pdf了吗?这不才刚读取了文章链接吗?这不还没读取文章内容呢嘛?
hiahiahiahia~这就要介绍一个引入的模块,一个神器!wkhtmltopdf是一个可以直接将网页转化为pdf的模块,也可以通过相应的函数设置网页指定部分转化为pdf。
当然我们还是要读取文章内容哒,但不需要单独设置函数读取文章了,在转为pdf的函数中直接读取,此处参考了Python 爬虫:把廖雪峰教程转换成 PDF 电子书。
https://foofish.net/python-crawler-html2pdf.html

依旧在chrome中打开简书文章右键“检查”,从图片中可以看出,title对应着标题,show-content对应着正文,代码如下,articlelist中存放着上一节读取的读者文章信息,这里使用的是Beautifulsoup匹配的源码信息。
for index,url inenumerate(articlelist): try: response = requests.get(url[1]) soup = BeautifulSoup(response.content,"html.parser") title = soup.find('h1').get_text() #写入标题 body = soup.find_all(class_="show-content")[0] #写入正文#标题加入到正文的最前面,居中显示 center_tag = soup.new_tag("center") title_tag = soup.new_tag('h1') title_tag.string = title center_tag.insert(1, title_tag) body.insert(1, center_tag) html = str(body) pattern = "(<img.*?src=")(//upload.*?)(")"def func(m): if not m.group(2).startswith("http"):#检查是否以http开头 rtn = "".join([m.group(1), "http:", m.group(2), m.group(3)]) return rtn else: return"".join([m.group(1), m.group(2), m.group(3)]) html = re.compile(pattern).sub(func, html) #将图片相对路径转为绝对 html = html_template.format(content=html) html = html.encode("utf-8") f_name = ".".join([str(index),"html"]) with open(f_name, 'wb') as f: f.write(html) htmls.append(f_name) except Exception as e: print etry: pdfkit.from_file(htmls, authorname + "的文章合辑.pdf", options=options)#将html文件合并为pdfexcept Exception as e: print efor html in htmls: os.remove(html) #删除缓存的html文件

pdf效果(mac)
Mac字有点小QAQ,看下windows的。

pdf效果(windows)
(*^__^*)
4.5 获取词云
在写程序的过程中,又增加了一个想法,在python中使用词云分析简书作者文章的关键词,于是又多写了几行。没有甲方的程序,想加什么功能就加什么功能(比剪刀手)。
思路是根据在4.3节中提取的文章链接,读取文章中文本内容,输出到txt文件中,再使用python的第三方模块jieba(这个模块中文翻译是结巴?结巴!结巴……哈哈哈哈哈哈嗝),通过这个模块,就可以将大段的文本按照词汇分开,而且支持中文分词!不要问我这个分词有啥用,计算机不是学过中文的,在它看来中文都是@!#¥%…&*。
filePath = './纯文章.txt'fileArticle = open(filePath, 'w')try: for article in articlelist: fileArticle.write(article[3])finally: fileArticle.close()text = open(filePath).read()os.remove(filePath)#使用jieba整理文本wordlist = jieba.cut(text,cut_all = False)wl = "/ ".join(wordlist)f_stop = open(stopwords_path)try: f_stop_text = f_stop.read() f_stop_text=unicode(f_stop_text,'utf-8')finally: f_stop.close()f_stop_seg_list = f_stop_text.split('n')for myword in wl.split('/'): ifnot(myword.strip() in f_stop_seg_list) andlen(myword.strip())>1: mywordlist.append(myword)text = ''.join(mywordlist)得到经过分词后的文件,使用python的第三方模块wordcloud输出词云,wordcloud模块可以引入自定义图片,并根据图片的轮廓生成词云,同时支持引入字体。
wc.generate(text)# 生成词云, 用generate输入全部文本,也可以我们计算好词频后使用generate_from_frequencies函数image_colors = ImageColorGenerator(back_coloring) # 从背景图片生成颜色值plt.figure() #绘制图片wc.to_file(imgname1) # 保存图片plt.figure()plt.imshow(wc.recolor(color_func=image_colors))wc.to_file(imgname2) # 保存图片我曾想过以作者头像为背景图生成词云,但发现有些作者的头像生成词云的效果并不好,于是我选择了固定图片作为词云背景,生成了怀左同学的词云。

怀左同学文章词云
怀左同学果然是学霸呀(●─●),努力、生活、写作、读书、学习……
好!我也决定要努力学习编程,努力工作(flag*MAX),不说了!我去努力了!(逃
我又回来了,gayhub源文件已上传,随意下载
代码均设置了时间间隔,虽然只是很小的爬虫,但是也不要给简书叔叔增加服务器压力啦~对啦,代码是基于Python2.7哒~
关于python基础入门的学习资料,我推荐这本书,Python 2.7教程,里面也有python3的教程。
https://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000
如果有什么关于代码的疑问欢迎质询,我会本着科♂学的态度认真回复的:在我的电脑上跑是好的。(再逃
4.6 揭开json的面纱
我会读取json文件啦。
情况是这样的,之前程序的设定是输入所需要作者的个人主页链接,但我希望程序是只需要输入作者的名字就可以运行。
于是我分析出搜索页的网址:"http://www.jianshu.com/search?q=怀左同学&page=1&type=user",查看源代码,发现源代码中没有搜索结果的显示(和说好的不一样啊!这不科学啊!)。
查了很多资料,大概知道这是网页的异步加载,于是又要动用chrome的另一个神器,检查-network了。

与4.2节相同,在搜索结果页中刷新页面,发现在xhr分类下多了俩个文件,点击第一个文件,查看右下角的preview,列表里不正是我们需要的搜索结果吗?那么怎么把它提取出来呢?
一般情况下我是查看preview旁边的headers选项卡中的requests URL:http://www.jianshu.com/search/do?q=%E6%80%80%E5%B7%A6%E5%90%8C%E5%AD%A6&type=user&page=1&order_by=default,但点击这个URL之后发现没有任何内容。
一开始我以为我努力的方向错了,在散发着大神之光的程序员小哥哥前辈的指点下,我下载了一个chrome插件:postman,将刚刚的网址粘贴到postman的浏览器中,发现打开之后就是我需要的内容!
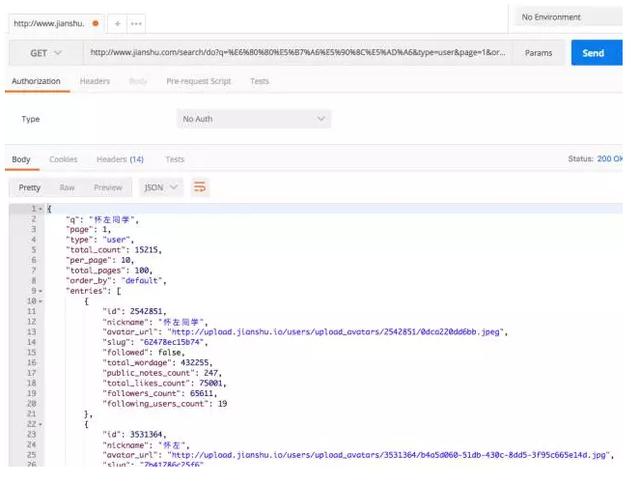
经过一番努力,知道了用这个链接直接在浏览器请求无法得到正确的网页内容是因为没有带正确的headers。
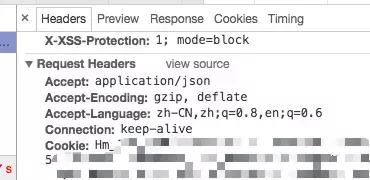
依然在chrome的检查中查看这个headers中的request header,将这些内容全部贴到代码的请求头中,全部代码如下。
defgetUrl(): userlink = [] while len(userlink) == 0: authorname = raw_input('请输入想查询的作者的名称:') url = "http://www.jianshu.com/search/do?q=" + authorname +"&type=user&page=1&order_by=default" headers = { 'User-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:55.0) Gecko/20100101 Firefox/55.0', 'Host' : 'www.jianshu.com', 'Accept' : 'application/json', 'Accept-Language' : 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3', 'Accept-Encoding' : 'gzip, deflate', 'Referer' : 'http://www.jianshu.com/search?q=' + authorname +'&page=1&type=user', 'Cookie' : '出现的cookies信息', 'DNT' : '1', 'Connection' : 'keep-alive', 'If-None-Match' : 'W/"89003709c764d0a3ece1d180f5d1c7df"', 'Cache-Control' :'max-age=0' } json_data = requests.get(url = url ,headers = headers).json() #获取网页中的json文件。for i in json_data['entries']: nickname = i['nickname'] slug = i['slug'] if nickname == authorname: return slug breakelse: print'输入的作者名称不符合规范,请重新输入。'这里需要了解关于python中json和浅拷贝与深拷贝的知识点,可以看到(如果你看不到请上翻页面到postman那里再看一遍图),我们需要匹配的内容在entries的nickname下,而需要得到的内容是与nickname同一组的slug值,slug值其实就是作者个人主页/u/后面的唯一标识码,遍历即可匹配啦~





